How should I pronounce your name?
Improving the performance of Voice Conversion technologies
Has your name ever been mispronounced? This project started off with the motivation to pronounce names of students from all around the world correctly in the voice of an announcer at graduation ceremonies! Check out our paper and github repository for more details!
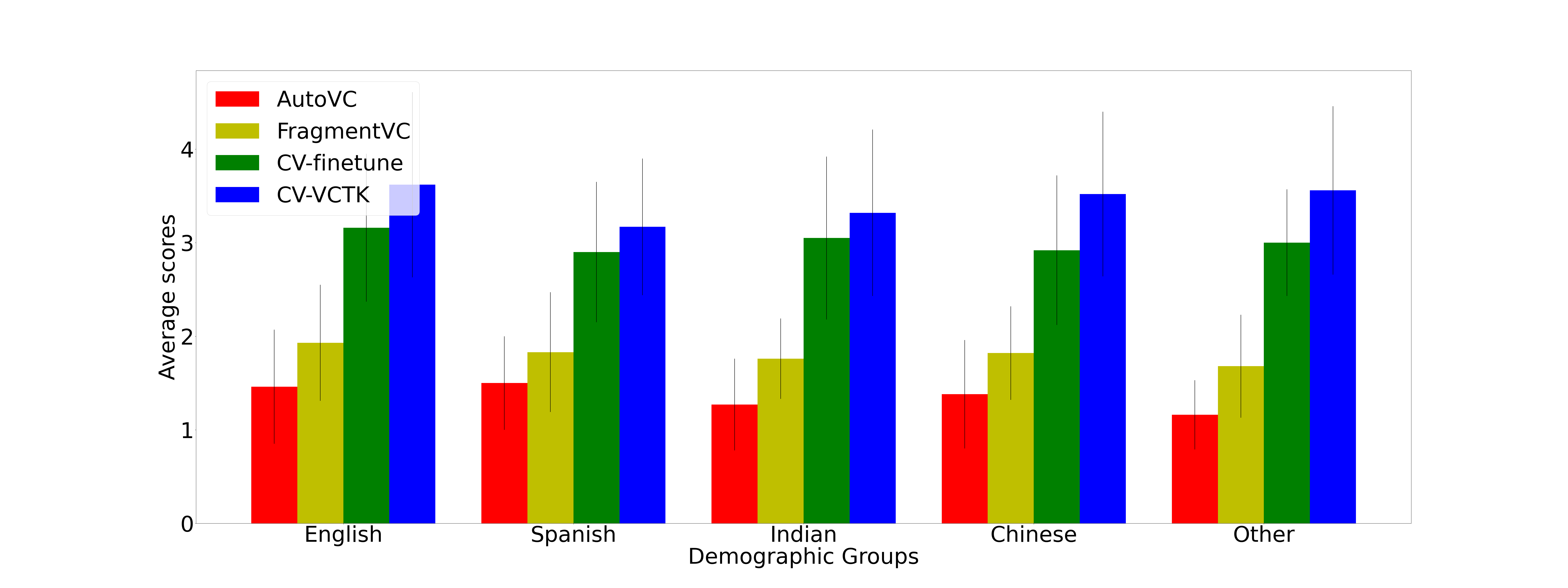
In this project, we explored SOTA Voice Conversion (VC) models such as fragmentvc and autovc and saw that they have impressive few shot conversion quality! However, when source or target speech accents, background noise conditions or mic characteristics differ from training, the performance of voice conversion is not guaranteed.
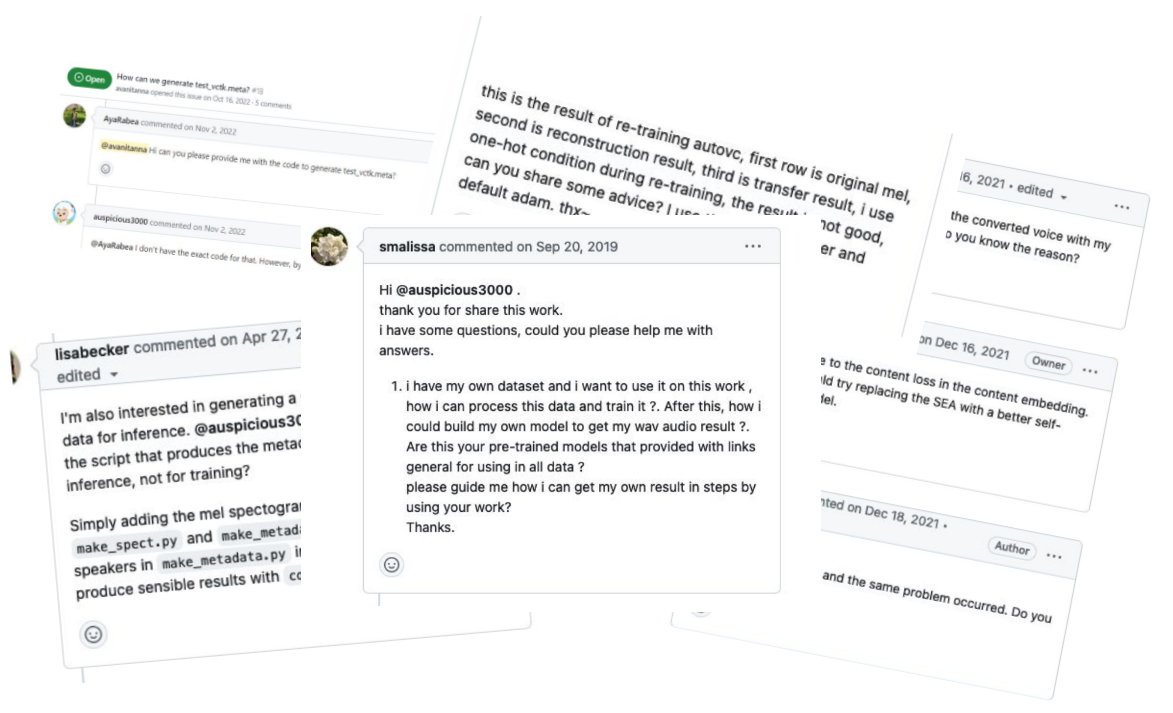
Its often challenging to document how to record quality utterances that’ll work well with a VC model. In fact, we observed that sampling rate, noise/vol levels, mic quality, clarity of speech all had significant impact on the output. We also saw that so many real-world users were frustrated while trying to use VC models on their own data (as evidenced by the litany of github issues). Among others, one of the issues is that these VC models are overfit to clean VCTK data (native English speakers).
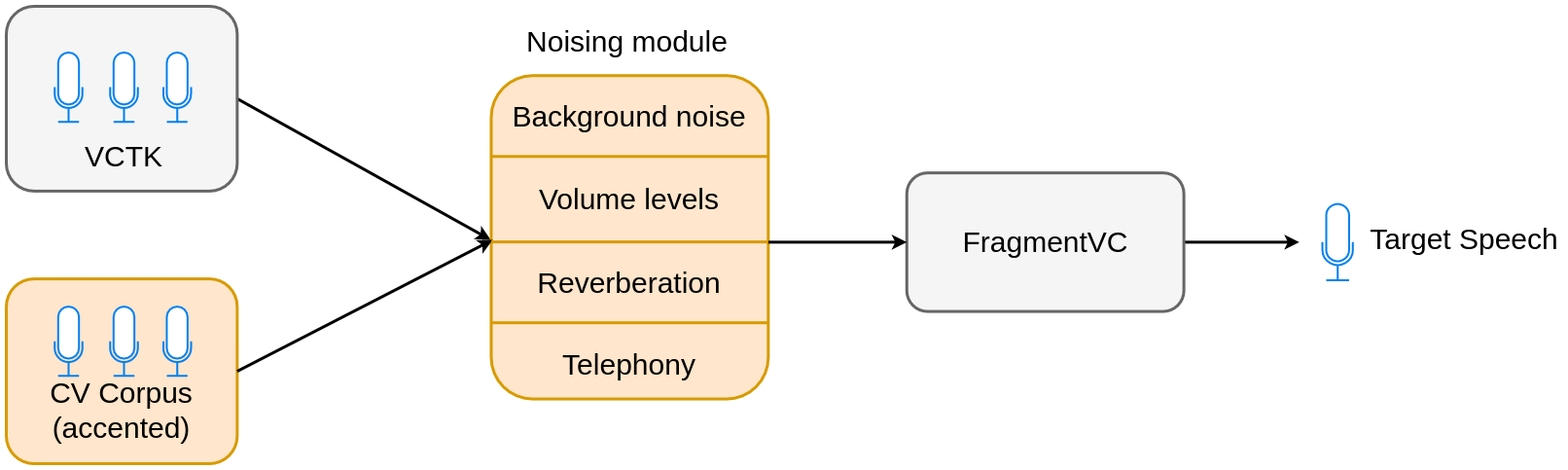
In light of this and motivated by a real-world application, we introduce a robust variant of fragmentvc - where we adapt the model via data augmentation during the training (we augment CV data with accented english speech) and a noising module that adds randomly sampled effects to the data during feature extraction.
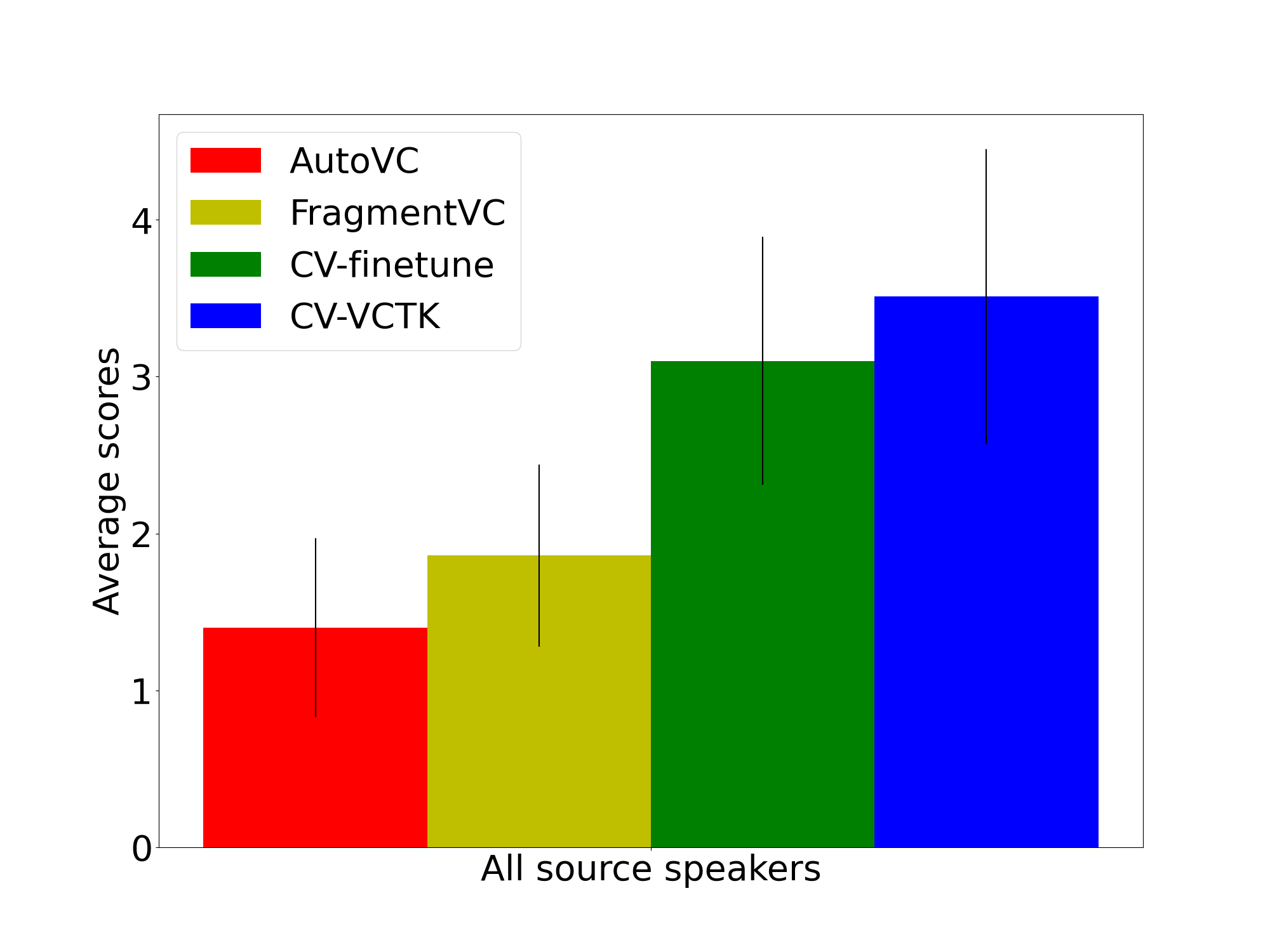
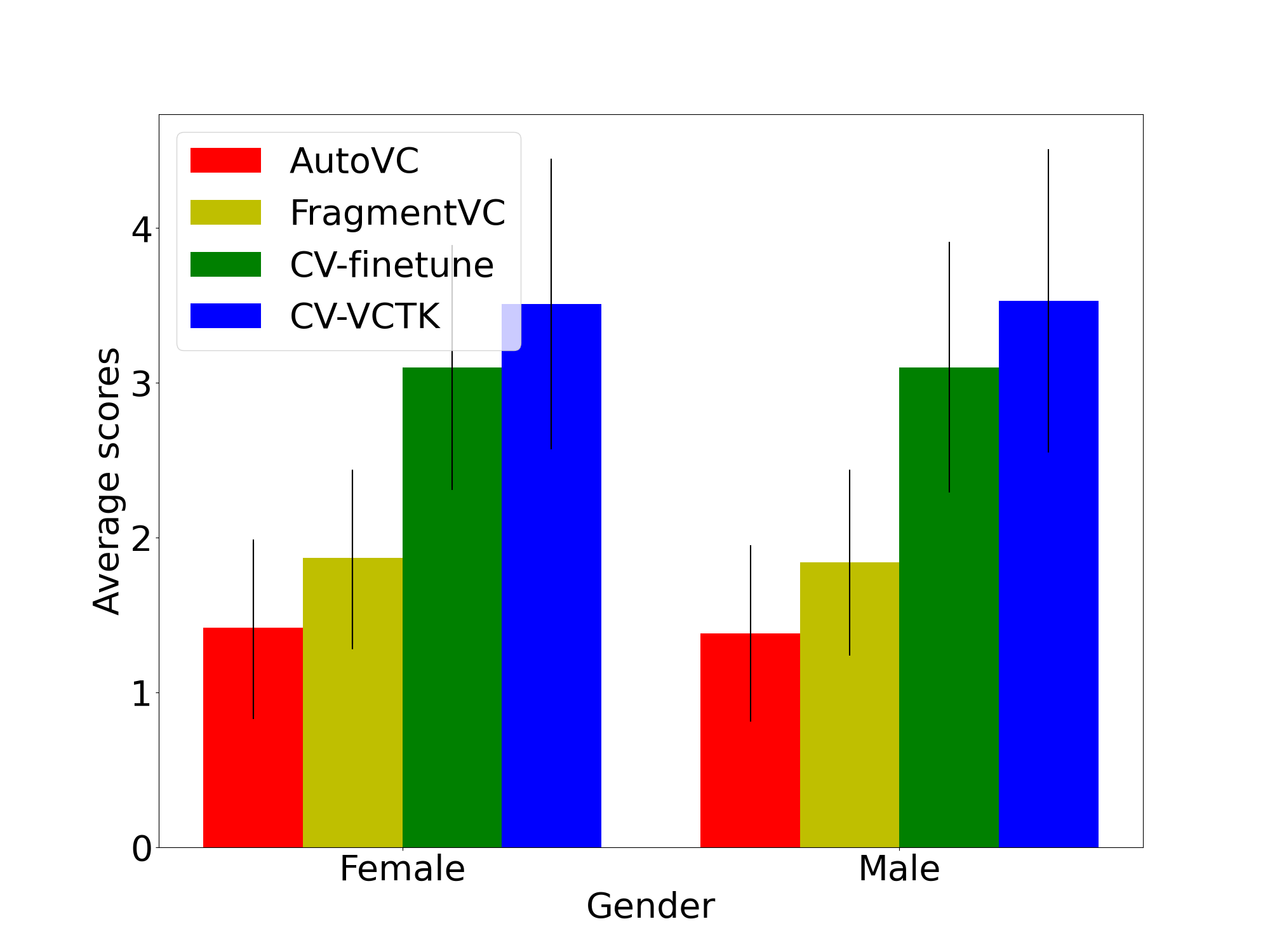
In doing so, we see that it is in fact possible to adapt SOTA models easily and improve their performance and help real-world users with a better checkpoint that they can use on their own data.

<!--
See https://www.debugbear.com/blog/responsive-images#w-descriptors-and-the-sizes-attribute and
https://developer.mozilla.org/en-US/docs/Learn/HTML/Multimedia_and_embedding/Responsive_images for info on defining 'sizes' for responsive images
-->
<source
class="responsive-img-srcset"
srcset="/assets/img/CollageWide-480.webp 480w,/assets/img/CollageWide-800.webp 800w,/assets/img/CollageWide-1400.webp 1400w,"
type="image/webp"
sizes="95vw"
>
<img
src="/assets/img/CollageWide.png"
class="img-fluid rounded z-depth-1"
width="100%"
height="auto"
title="Litany of github issues"
loading="lazy"
onerror="this.onerror=null; $('.responsive-img-srcset').remove();"
>
</picture>
</figure>
</div>
</div>
In light of this and motivated by a real-world application, we introduce a robust variant of fragmentvc - where we adapt the model via data augmentation during the training (we augment CV data with accented english speech) and a noising module that adds randomly sampled effects to the data during feature extraction.

In doing so, we see that it is in fact possible to adapt SOTA models easily and improve their performance and help real-world users with a better checkpoint that they can use on their own data.




–>